2026年6月16日,第306期外语论坛·专家论道如期举行,来自意大利Università Cattolica del Sacro Cuore的Marco Carlo Passarotti教授以“LiLa (and LiITA) and Lexicography. Exploiting the Interaction between Lexical (and Textual) Resources”为题,聚焦关联数据(Linked Data)问题,分享了LiLa和LiITA两大项目的技术架构、应用实践与未来方向。我院副院长耿云冬与法国CY Cergy Paris Université的陈恋副教授为本次讲座召集人,来自葡萄牙NOVA University Lisbon的教授担任讲座主持人。
讲座伊始,Passarotti指出,当前各类语料库、词典、语言处理工具等语言资源彼此割裂,格式、标注标准不一,整合难度较大。而遵循FAIR准则(即Findability、Accessibility、Interoperability、Re-usability)的关联数据可有效解决这一问题,依托URI标识符、HTTP开放协议与标准化模型,打通资源使用壁垒。此外,Passarotti进一步讲解了RDF Schema与SPARQL查询语言的运行逻辑,区分不同数据属性,强调语义建模是实现语言资源深度融合的核心工作。
随后,Passarotti重点介绍了同源项目LiLa与LiITA。LiLa面向拉丁语,依托欧洲研究理事会基金建成并持续发展,LiITA则聚焦意大利语。两个项目均以词元库为核心枢纽,串联起不同词汇资源中的词条与语料库内的词汇实例,实现多类语言资源联动检索。
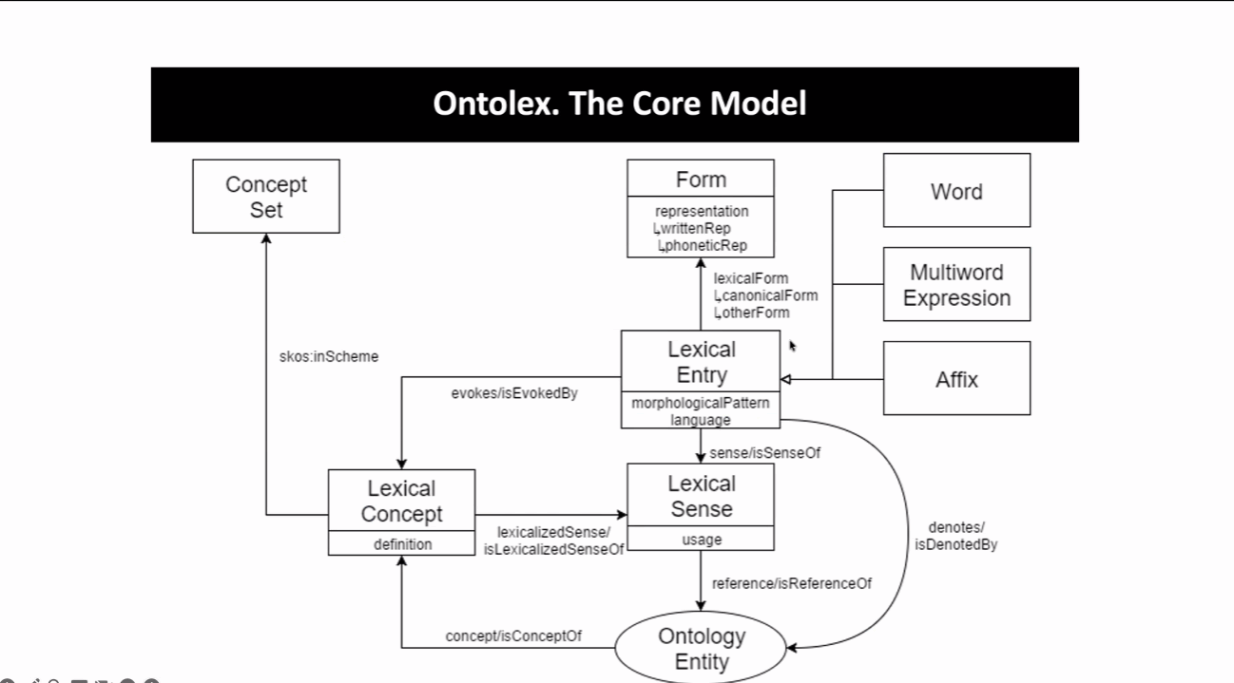
Ontolex是两大项目的核心模型。该模型以词条、词汇形态、词义为核心实体,将词语各类形态统一对应至词元(lemma),同时依托句法、语义、构词、翻译等拓展模块,全面覆盖词语配价、形态变化、跨语言对照、条目解析等功能,可高效完成传统词典向语义网络的数字化转型。
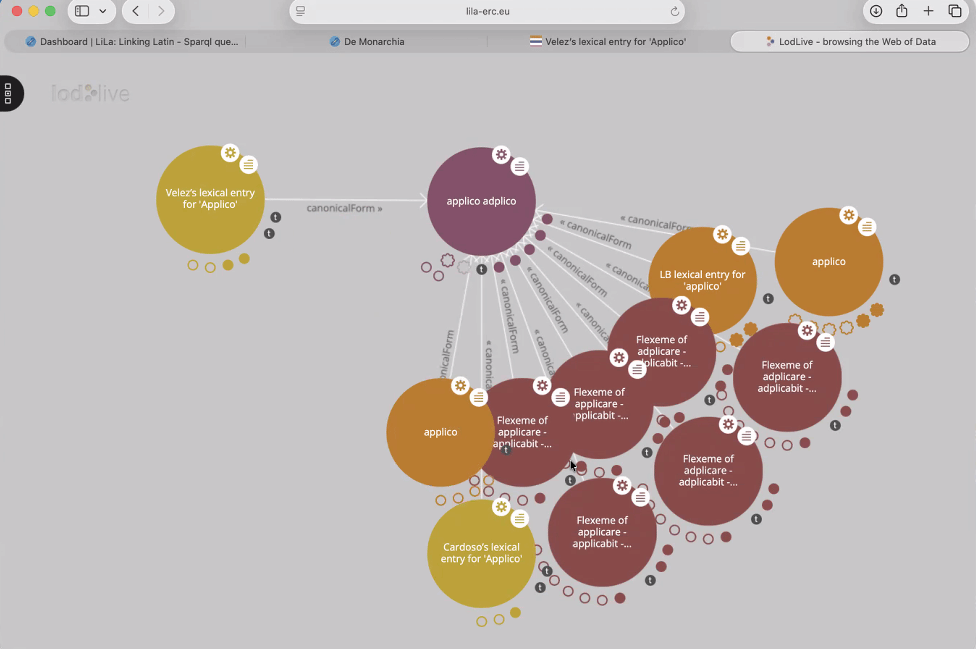
目前LiLa项目收录约17万个词元、27万个字形变体,整合17项词汇资源;LiITA项目词元数量约16万个。两大知识库均拥有海量RDF三元组数据,项目团队也在持续补充完善词元库内容。为降低使用门槛,项目配套了多款实用工具:1)可视化检索界面:支持多条件筛选并展示综合信息;2)文本链接工具:自动完成分词、词性标注,并以不同颜色区分词元匹配状态;3)SPARQL查询接口:满足专业学者深度数据挖掘的需求。结合词典、词源资料等实例,Passarotti直观展示了关联数据在词典数字化中的突出价值。
讲座最后,Passarotti提出了项目的未来发展方向:1)借助大语言模型优化歧义词元自动消歧能力;2)依托现有架构拓展语种,搭建跨语言词汇关联网络;3)研发文本转SPARQL功能,简化检索操作;4)将知识库中的结构化领域知识注入大语言模型,弥补其在专业领域的短板,同时实现词典条目半自动编撰。
互动环节中,与会学者围绕词元库界定、数据呈现、AI与传统词汇资源协同等问题展开探讨。针对词元库的属性争议,Passarotti表示,按照Ontolex的标准,词元库是衔接各类资源的中间枢纽,不属于传统词汇资源,但若从广义角度划分,也具备词汇信息集合的特征,需结合具体场景判定。
整场讲座理论结合实践,清晰展现了关联数据(Linked Data)为词典学与计算语言学带来的变革。LiLa与LiITA的项目实践证明,标准化关联技术能够打破语言资源壁垒,而关联数据与人工智能的融合,也将推动语言资源朝着开放化、智能化、互联化的方向持续发展。本次讲座为2025年度国家外国专家项目“智能辞书编纂的国际前沿与本土创新”(项目编号:H20250649)资助的系列学术活动之一。
【专家简介】Marco Carlo Passarotti,现为意大利Università Cattolica del Sacro Cuore计算语言学全职教授,该校CIRCSE研究中心创始人兼现任主任。自2006年起,主持索引托马斯语料库树库项目,2018年起担任欧洲研究理事会整合基金项目LiLa首席研究员,同时参与伊拉斯谟世界数据语言科学联盟、LexAI等多项重要国际科研项目。Passarotti深耕计算语言学、古典语言语料库标注、依存句法分析、词汇学以及语言关联数据等领域,聚焦拉丁语与意大利语语言资源数字化、智能化建设,累计发表学术论文170余篇,出版多部学术著作与章节成果,研究成果广泛应用于古典文献数字化、词典学、自然语言处理等方向。

